
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 프로그래머스
- 코딩테스트
- 깃허브
- 코딩스터디
- codepresso
- MySQL
- 슥삭
- 매직메서드
- API 명세서
- 무료코딩교육
- 타입스크립트
- AI코칭스터디
- Elastic Search
- 네이버커넥트재단
- NCP
- 엘라스틱서치
- 리액트
- 코딩이러닝
- GitLab
- 자바스크립트
- reduce()
- 코드프레소
- IT교육
- markdown
- git
- 마크다운
- 네이버클라우드플랫폼
- 코딩강의
- 무료IT교육
- 대외활동
- Today
- Total
개발하는 무민
[AI Basic 코칭스터디] 파이썬 팀 과제 정리 (+스터디 후기) 본문

네이버 커넥트 재단에서 운영하는 부스트코스의 AI Baisc 1기에 참여하여 AI 코칭 스터디를 2개월간 진행했다.
수업은 모두 온라인으로 진행되어 일 하면서도 듣기 편했었고, 매주 라이브로 피드백도 해주셔서 많은 내용을 배울 수 있었던 것 같다.
이 스터디 이외에도 다른 수업이나 공모전 등을 준비하느라 시간이 많이 없어서 꼼꼼하게 공부하진 못했지만... 끝까지 참여했다는 것에 의의를 둔다 ^__^
블로그에는 코칭 스터디를 진행하면서 내가 풀었던 과제들을 정리하고자 한다.
스터디는 팀으로 구성되어 진행됐고, 매주 미션이 출제되면 팀원들이 나눠서 푸는 형태였다.
회사에서도 일하면서 틈틈히 풀어야 했어서 따로 환경설정이 필요 없는 코랩이나 웹 IDE를 많이 이용했다.
파이썬은 문법도 간단하면서 복잡한 환경설정이 필요하지 않아서 정말 간단하고 똑똑한 언어인 것 같다.
1주차
📌Q3. 이번 학기의 중간고사, 기말고사 점수가 발표되었습니다. 각 학생들의 점 수가 튜플 형태로 저장되어 있고, 이를 포함한 리스트가 있습니다. 이를 이용 해 각 학생들의 평균 점수를 출력하는 함수를 제작하세요. 😎
- 리스트와 반복문을 사용해 데이터를 불러오세요.
- 이를 이용해 각 학생별 평균을 구해보세요
답
score = [(100, 100), (95, 90), (55,60), (75,80), (70,70)] #각 학생들의 점수(5명)
def get_avg(score): #평균을 구하기 위한 함수 정의
for i in range (len(score)): #리스트의 길이만큼 반복문 실행
sum_score = sum(score[i]) #i번째 튜플 안의 점수를 더한 값 계산
avg_score = sum_score/2 #*더한 값을 점수 개수만큼 나눠서 평균 값 계산
print(f"%d 번, 평균 : {avg_score:.1f}" % (i+1)) #학생의 점수 출력 (소숫점 조절을 위해 f-string 사용)
get_avg(score) #구현한 함수 실행
2주차
📌Q3. 이번 시험 결과에 대한 데이터를 학과 사무실에서 CSV파일로 전달해줬습니다. 우리는 이 파일을 이용해서 데이터 처리를 진행해야 합니다. 파일 입출력을 이용해 파일 데이터를 리스트로 만들어보세요.
- 파일 입출력에 사용하는 open 함수를 이용해 CSV 파일 내부의 데이터를 읽어보세요
**CSV파일은 아래 첨부되어있습니다.
답
#Q3
import csv #csv 파일을 읽어들이기 위해 라이브러리를 import
def read_file(file_path):
file_path = "./data-01-test-score.csv" #오픈할 파일의 경로 설정
file = open(file_path,'r') #open 함수를 사용해서 오픈할 파일 오브젝트를 생성하기 위해 파일의 경로를 인자로 건넨다
csv_r= csv.reader(file) #open을 통해 생성한 파일 오브젝트(file)을 csv.reader라는 함수로 읽어들인 값을 csv_r에 저장한다
for line in csv_r: #for문을 통해 저장된 값을 반복해서 돌며 한개씩 출력해준다.
print(line)
f.close() #열었던 파일을 닫아준다.
print(read_file(read_csv))
📌Q4. 우리는 방금 CSV 파일을 읽는 함수를 구현해보았습니다. 하지만 이를 조금 더 효율적으로 사용하기 위해서 클래스로 구성을 진행하려고 합니다. 방금 구현한 함수를 포함한 클래스를 구현해보세요.
- merge list를 이용해 리스트 내 데이터의 합을 출력해보세요.
- 데이터를 합치기 전 데이터의 자료형을 변경해보세요.
답
#Q4
import csv
class ReadCSV():
def __init__(self, file_path):
self.file_path = file_path
def read_file(self):
file_path = "./data-01-test-score.csv" #오픈할 파일의 경로 설정
file = open(file_path,'r') #open 함수를 사용해서 오픈할 파일 오브젝트를 생성하기 위해 파일의 경로를 인자로 건넨다
csv_r= csv.reader(file) #open을 통해 생성한 파일 오브젝트(file)을 csv.reader라는 함수로 읽어들인 값을 csv_r에 저장한다
for line in csv_r: #for문을 통해 저장된 값을 반복해서 돌며 한개씩 출력해준다.
print(line)
f.close() #열었던 파일을 닫아준다.
def merge_list(self):
file_path = "./data-01-test-score.csv" #오픈할 파일의 경로 설정
file = open(file_path,'r') #open 함수를 사용해서 오픈할 파일 오브젝트를 생성하기 위해 파일의 경로를 인자로 건넨다
csv_r= csv.reader(file) #open을 통해 생성한 파일 오브젝트(file)을 csv.reader라는 함수로 읽어들인 값을 csv_r에 저장한다
merge_list = [] #merge한 리스트를 저장할 공간 생성
for line in csv_r: #for문을 통해 저장된 값을 반복해서 돌며 한개씩 출력해준다.
intList = [int(x) for x in line] #str으로 되어있는 리스트의 요소를 int로 변경
sum1 = sum(intList) #int로 변경한 리스트의 요소를 sum 함수를 통해 합산해준다
merge_list.append(sum1) #합산한 값을 리스트에 저장해준다
print(merge_list) #merge된 리스트 출력하기
f.close() #파일 사용 종료 후 닫아주기
file_path = "./data-01-test-score.csv"
read_csv = ReadCSV(file_path)
print(read_csv.read_file())
print(read_csv.merge_list())
📌Q5. 이전에 구현한 클래스에서 merge_list의 함수 동작을 변경해야합니다. 단순합계가 아닌 평균을 구하는 함수로 변경해보세요.
- 리스트의 데이터를 다루는 함수를 이용해서 구현해보세요.
- 최종 평균을 구한 후 오름차순으로 정렬해주세요.
답
#Q5
import csv
class ReadCSV():
def __init__(self, file_path):
self.file_path = file_path
def read_file(self):
file_path = "./data-01-test-score.csv" #오픈할 파일의 경로 설정
file = open(file_path,'r') #open 함수를 사용해서 오픈할 파일 오브젝트를 생성하기 위해 파일의 경로를 인자로 건넨다
csv_r= csv.reader(file) #open을 통해 생성한 파일 오브젝트(file)을 csv.reader라는 함수로 읽어들인 값을 csv_r에 저장한다
for line in csv_r: #for문을 통해 저장된 값을 반복해서 돌며 한개씩 출력해준다.
print(line)
f.close() #열었던 파일을 닫아준
def merge_list(self): #평균값을 구하는 함수 만들기
file_path = "./data-01-test-score.csv" #오픈할 파일의 경로 설정
file = open(file_path,'r') #open 함수를 사용해서 오픈할 파일 오브젝트를 생성하기 위해 파일의 경로를 인자로 건넨다
csv_r= csv.reader(file) #open을 통해 생성한 파일 오브젝트(file)을 csv.reader라는 함수로 읽어들인 값을 csv_r에 저장한다
merge_list = [] #merge한 리스트를 저장할 공간 생성
for line in csv_r: #for문을 통해 저장된 값을 반복해서 돌며 한개씩 출력해준다.
intList = [int(x) for x in line] #str으로 되어있는 리스트의 요소를 int로 변경
sum1 = sum(intList) #int로 변경한 리스트의 요소를 sum 함수를 통해 합산해준다
avg1 = sum1/4
merge_list.append(avg1) #평균값을 리스트에 저장해준다
merge_list.sort() #오름차순 정렬
print(merge_list) #merge된 리스트 출력하기
f.close() #파일 사용 종료 후 닫아주기
file_path = "./data-01-test-score.csv"
read_csv = ReadCSV(file_path)
print(read_csv.merge_list())
3주차
📌Q1. 본격적으로 Numpy와 친해지기 위해서 다양한 연산을 연습해볼 예정입니다. 무작위의 데이터를 가 진 5x3의 행렬을 가지는 numpy array와 3x2 행렬을 가지는 numpy array를 만든 후 행열곱 연산을 진행해보세요.
답
import numpy as np
arr1 = np.random.rand(5, 3) #5x3의 무작위 행렬 생성
arr2 = np.random.rand(3, 2) #3x2의 무작위 행렬 생성
dot = arr1.dot(arr2) #내적 연산 실행
print(dot, dot.shape) #결과값 출력
4주차부터는 정답 예시코드를 같이 올려주셨다.
정답 예시 코드

4주차
📌Q2. 두번째로 Pandas에서 지원하는 Dataframe을 다뤄보도록 하겠습니다. 다음과 같이 과일과 야채 각각 정리된 데이터가 있습니다. 이 두 데이터를 따로 보기엔 효율성이 떨어지니, 각 표에 정리된 데이터를 각각 하나의 데이터 프레임으로 생성한 후 다음 세부 구현을 진행해보세요.
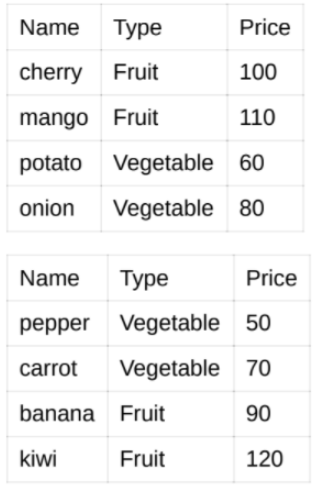
- 두 데이터를 하나의 데이터로 결합해보세요.
- 결합한 데이터의 type을 이용해 데이터를 정렬해보세요.
- 최종적으로 과일과 야채 중 가장 비싼 가격의 합을 출력해보세요.

답
import pandas as pd
#df1 생성
df1 = pd.DataFrame({"Name":["cherry","mango","potato","onion"],
"Type":["Fruit","Fruit","Vegetable","Vegetable"],
"Price":[100,110,60,80]})
#df2 생성
df2 = pd.DataFrame({"Name":["pepper","carrot","banana","kiwi"],
"Type":["Vegetable","Vegetable","Fruit","Fruit"],
"Price":[50,70,90,120]})
#df1과 df2를 concat을 이용해 결합한 데이터프레임 df3 생성
df3 = pd.concat([df1,df2])
#Fruit와 Vegetavle의 type에 따라 정렬하고, 가격을 내림차순으로 정리
df_Fruit = df3[df3['Type'].str.contains('Fruit')] #Fruit이 포함된 데이터만 추출
df_Fruit = df_Fruit.sort_values('Price', ascending=False) #Price를 기준으로 내림차순 정렬
df_Veg = df3[df3['Type'].str.contains('Vegetable')] #Vegetable이 포함된 데이터만 추출
df_Veg = df_Veg.sort_values('Price', ascending=False) #Price를 기준으로 내림차순 정렬
#Fruit와 Vegetable 상위 2개의 가격의 합 출력
print("Sum of Top 2 Fruit Price :", df_Fruit.iloc[0]['Price'] + df_Fruit.iloc[1]['Price']) #0번째 값과 1번째 값 추출
print("Sum of Top 2 Vegetable Price :", df_Veg.iloc[0]['Price'] + df_Veg.iloc[1]['Price']) #0번째 값과 1번째 값 추출
정답 예시 코드

5주차
📌Q1. 가장 먼저 학습 데이터를 준비해보도록 하겠습니다. MNIST 데이터셋을 직접 Load해 봅시다. 데이터셋을 로드하고 DataLoader를 구현해보세요.
- DataLoader를 이용해 MNIST 데이터셋을 로드해봅시다.
📌Q2.데이터가 준비가 되었다면, 이제 그 데이터를 학습할 모델을 구현할 차례입니다. 그후 모델 안의 가중치를 초기화시켜보세요. 입력 데이터 형태에 맞도록 linear한 모델을 구성해보세요.
- MNIST 입력의 크기는 28x28입니다.
- 여기서 구현하는 linear 모델은 입력이 1차원이기 때문에 입력 차원을 맞춰보세요.
📌Q3. 위에서 구현한 모델을 학습시키기 위해서는 loss 함수와 opitmizer가 필요합니다.아래 제시된 loss 함수와 optimizer를 구현해보세요. Loss 함수와 optimizer는 모델 안의 가중치를 업데이트 할 때 사용됩니다.
- 옵티마이저는 SGD, Loss는 Cross Entropy Loss를 사용합니다.
📌Q4. 3번 문제까지 해결하셨다면, 이제 학습을 위한 준비는 거의 끝났다고 볼 수 있습니다.위 구현 함수들을 이용해 학습 Loop를 구현해보세요.
- 위에서 구현한 모델, optimzer, loss fn 등을 이용해 학습을 구현해주세요.
📌Q5. 학습이 완료되면, 모델이 잘 동작하는지 테스트가 필요합니다. 데이터로드 파트에서준비했던 테스트 데이터를 이용해 테스트를 진행해봅시다. 아래 테스트 코드를 완성해보세요.
답(실습)
from keras.datasets import mnist
(x_train, _), (x_test, _) = mnist.load_data() #mnist를 사용하기 위해 설치해주는 과정
# MNIST Database -> 손글씨 숫자 이미지 집합
import torch
import torch.nn as nn
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
training_epochs = 15 #트레이닝 15회 반복
batch_size = 100
root = './data'
mnist_train = dset.MNIST(root=root, train=True, transform=transforms.ToTensor(), download=True)
mnist_test = dset.MNIST(root=root, train=False, transform=transforms.ToTensor(), download=True)
# 데이터 로드하기
train_loader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(mnist_test, batch_size=batch_size, shuffle=False)
# 불러온 데이터를 학습할 모델 구현
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
linear = torch.nn.Linear(784, 10, bias = True).to(device)
torch.nn.init.normal_(linear.weight)
# loss 함수, optimizer 구현하기 (가중치 업데이트용)
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(linear.parameters(), lr=0.1)
# 학습 Loop 구현
for epoch in range(training_epochs):
for i, (imgs, labels) in enumerate(train_loader):
imgs, labels = imgs.to(device), labels.to(device)
imgs = imgs.view(-1, 28*28) #규격 설정
outputs = linear(imgs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, argmax = torch.max(outputs, 1)
accuracy = (labels == argmax).float().mean()
if (i+1) % 100 == 0:
print('Epoch [{}/{}]m Step [{}/{}], Loss: {:.4f}, Accuracy : {:2f}%'.format(
epoch+1, training_epochs, i+1, len(test_loader), loss.item(), accuracy.item() *100))
linear.eval()
with torch.no_grad():
correct = 0
total = 0
for i, (imgs, labels) in enumerate(test_loader):
imgs, labels = imgs.to(device), labels.to(device)
imgs = imgs.view(-1, 28 * 28)
outputs = linear(imgs)
_, argmax = torch.max(outputs, 1) # 최종 출력이 가장 높은 클래스 선택
total += imgs.size(0)
correct += (labels == argmax).sum().item()
print('Test accuracy for {} images: {:.2f}%'.format(total, correct / total * 100))
5주차는 정답 코드를 보고 따라하면서 실습했다.
코랩에서 한 블럭씩 실습하는게 편해서 5주차는 코랩을 사용했다.
https://colab.research.google.com/drive/12-xI4OfHNeXlXvZEGu485mjRp7glhN-d
AI스터디_5주차.ipynb
Colaboratory notebook
colab.research.google.com
모든 코드는 깃허브에 정리해서 올려놓았다.
https://github.com/wndnjs2037/AIBasic_Boostcourse
GitHub - wndnjs2037/AIBasic_Boostcourse: AIBasic BoostCourse Study 1st
AIBasic BoostCourse Study 1st. Contribute to wndnjs2037/AIBasic_Boostcourse development by creating an account on GitHub.
github.com

다음에도 이런 강의가 있다면 찾아서 들어봐야겠다.
'Development > Python' 카테고리의 다른 글
| [python] 매직메서드 (__init__) (0) | 2023.11.07 |
|---|
